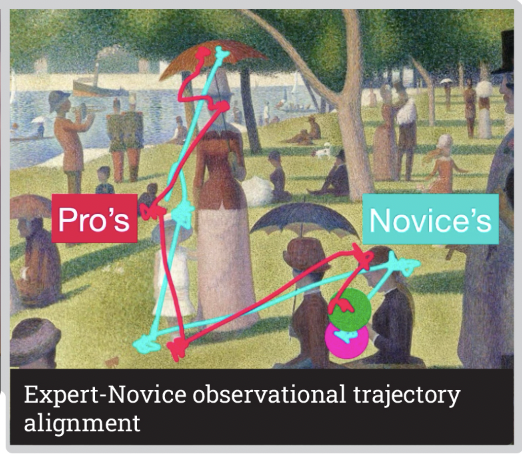
Learning to see the world like an expert is a critical step in mastering complex skills, yet transferring these implicit visual strategies remains a significant challenge. We present Pro’s Eyes, a wearable see-through display system designed to bridge this expert-novice gap by synchronizing a novice’s observational patterns with an expert’s. The system implicitly guides a user’s attention by creating a clear viewing aperture aligned with an expert’s gaze path while dimming the visual periphery. To validate our approach, we conducted a formal user study (N=17) focusing on an art appreciation task. The results provide strong empirical evidence of the system’s efficacy: Pro’s Eyes significantly improved gaze synchronization between novices and a pre-recorded expert’s path (p<.05) compared to free observation. Subjectively, participants reported that the guidance helped them identify details they would have otherwise missed. Our work’s primary contribution is an empirically-validated wearable system that demonstrates the potential of implicit gaze guidance for transferring expert observational skills.
@inproceedings{10.1145/3757373.3763766,author={Zhang, Qing and Huang, Jing and Itoh, Yuta and Starner, Thad and Kunze, Kai and Rekimoto, Jun},title={Pro's Eyes: A Wearable System for Synchronous and Asynchronous Observational Pattern Learning},year={2025},isbn={9798400721335},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3757373.3763766},doi={10.1145/3757373.3763766},booktitle={Proceedings of the SIGGRAPH Asia 2025 Emerging Technologies},articleno={15},numpages={2},keywords={Eye Tracking, Gaze Guidance, Skill Acquisition, Observational Learning, Smart Eyewear, Augmented Reality, Expert-Novice Learning, Wearable Computing, Programmable Vision},location={
},series={SA Emerging Technologies '25},}
NeurIPS Creative AI
Semantic Glitch: Agency and Artistry in an Autonomous Pixel Cloud
Qing Zhang, Jing Huang, Mingyang Xu, and 1 more author
In The Thirty-ninth Annual Conference on Neural Information Processing Systems Creative AI Track: Humanity, 2025
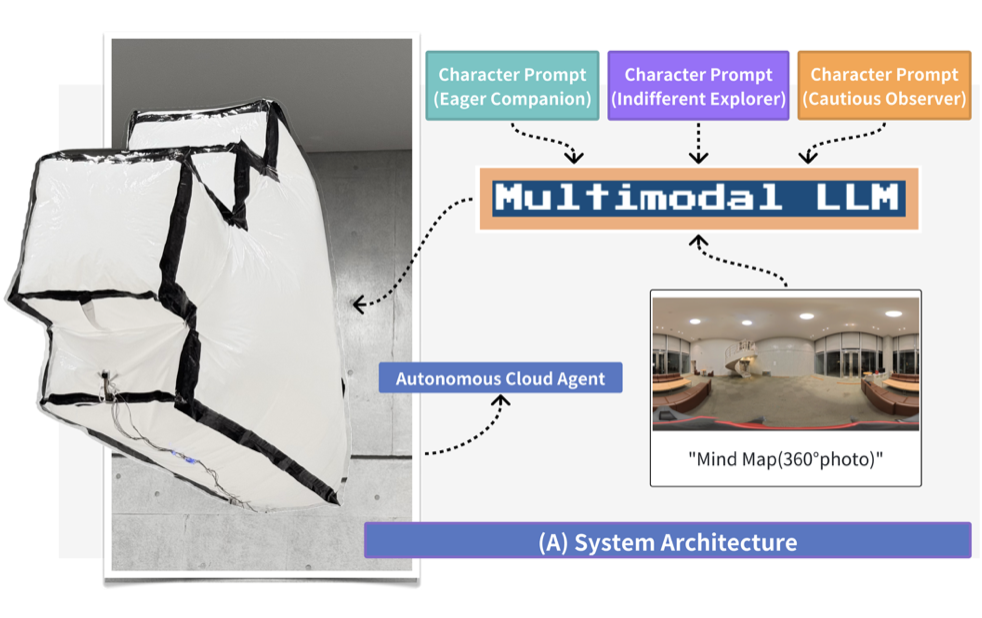
While mainstream robotics pursues metric precision and flawless performance, this paper explores the creative potential of a deliberately "lo-fi" approach. We present the "Semantic Glitch," a soft flying robotic art installation whose physical form, a 3D pixel style cloud, is a "physical glitch" derived from digital archaeology. We detail a novel autonomous pipeline that rejects conventional sensors like LiDAR and SLAM, relying solely on the qualitative, semantic understanding of a Multimodal Large Language Model to navigate. By authoring a bio-inspired personality for the robot through a natural language prompt, we create a "narrative mind" that complements the "weak," historically, loaded body. Our analysis begins with a 13-minute autonomous flight log, and a follow-up study statistically validates the framework’s robustness for authoring quantifiably distinct personas. The combined analysis reveals emergent behaviors, from landmark-based navigation to a compelling "plan to execution" gap, and a character whose unpredictable, plausible behavior stems from a lack of precise proprioception. This demonstrates a lo-fi framework for creating imperfect companions whose success is measured in character over efficiency.
@inproceedings{zhang2025semantic,title={Semantic Glitch: Agency and Artistry in an Autonomous Pixel Cloud},author={Zhang, Qing and Huang, Jing and Xu, Mingyang and Rekimoto, Jun},booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems Creative AI Track: Humanity},year={2025},url={https://openreview.net/forum?id=oul9LWDi9S},}
NeurIPS Creative AI
Panel-by-Panel Souls: A Performative Workflow for Expressive Faces in AI-Assisted Manga Creation
Qing Zhang, Jing Huang, Yifei Huang, and 1 more author
In The Thirty-ninth Annual Conference on Neural Information Processing Systems Creative AI Track: Humanity, 2025
Current text-to-image models struggle to render the nuanced facial expressions required for compelling manga narratives, largely due to the ambiguity of language itself. To bridge this gap, we introduce an interactive system built on a novel, dual-hybrid pipeline. The first stage combines landmark-based auto-detection with a manual framing tool for robust, artist-centric face preparation. The second stage maps expressions using the LivePortrait engine, blending intuitive performative input from video for fine-grained control. Our case study analysis suggests that this integrated workflow can streamline the creative process and effectively translate narrative intent into visual expression. This work presents a practical model for human-AI co-creation, offering artists a more direct and intuitive means of "infusing souls" into their characters. Our primary contribution is not a new generative model, but a novel, interactive workflow that bridges the gap between artistic intent and AI execution.
@inproceedings{zhang2025panelbypanel,title={Panel-by-Panel Souls: A Performative Workflow for Expressive Faces in {AI}-Assisted Manga Creation},author={Zhang, Qing and Huang, Jing and Huang, Yifei and Rekimoto, Jun},booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems Creative AI Track: Humanity},year={2025},url={https://openreview.net/forum?id=EI9PCu5oFp},}
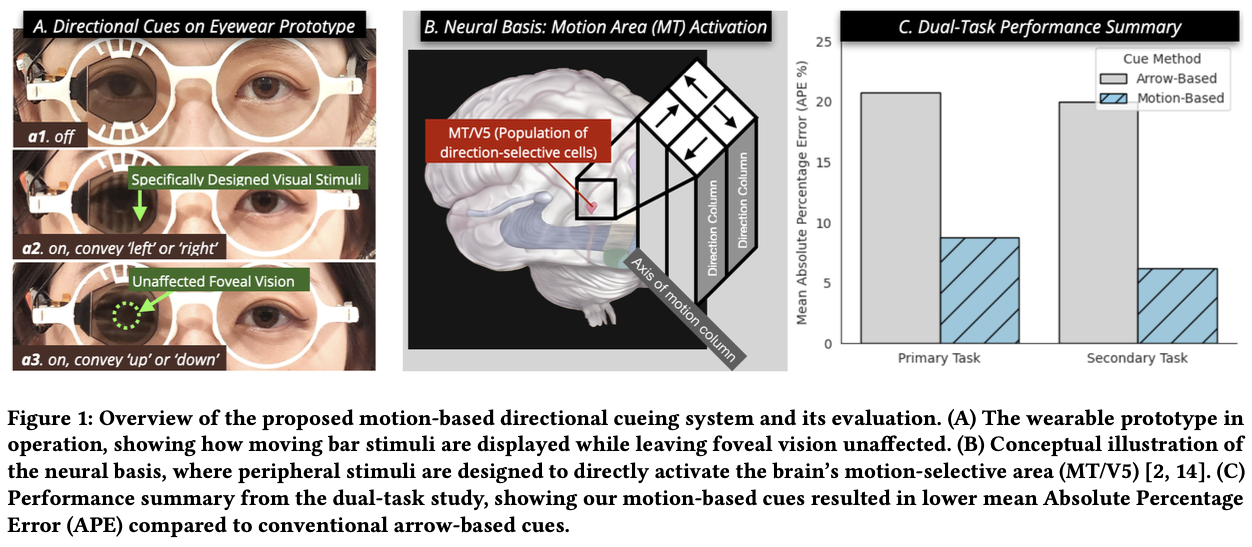
Directional cues are crucial for environmental interaction. Conventional methods rely on symbolic visual or auditory reminders that require semantic interpretation, a process that proves challenging in demanding dual-tasking scenarios. We introduce a novel alternative for conveying directional cues on wearable displays: directly triggering motion perception using monocularly presented peripheral stimuli. This approach is designed for low visual interference, with the goal of reducing the need for gaze-switching and the complex cognitive processing associated with symbols. User studies demonstrate our method’s potential to robustly convey directional cues. Compared to a conventional arrow-based technique in a demanding dual-task scenario, our motion-based approach resulted in significantly more accurate interpretation of these directional cues (p=.008) and showed a trend towards reduced errors on the concurrent primary task (p=.066).
@inproceedings{10.1145/3715071.3750418,author={Zhang, Qing and Chen, Junyu and Huang, Yifei and Huang, Jing and Starner, Thad and Kunze, Kai and Rekimoto, Jun},title={Beyond Symbols: Motion Perception Cues Enhance Dual-Task Performance with Wearable Directional Guidance},year={2025},isbn={9798400714818},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3715071.3750418},doi={10.1145/3715071.3750418},booktitle={Proceedings of the 2025 ACM International Symposium on Wearable Computers},pages={22–29},numpages={8},keywords={directional cues, dual-tasking, motion perception, non-symbolic cues, peripheral vision, programmable vision, wearable displays},location={Espoo, Finland},series={ISWC '25},}
SIGGRAPH E-Tech
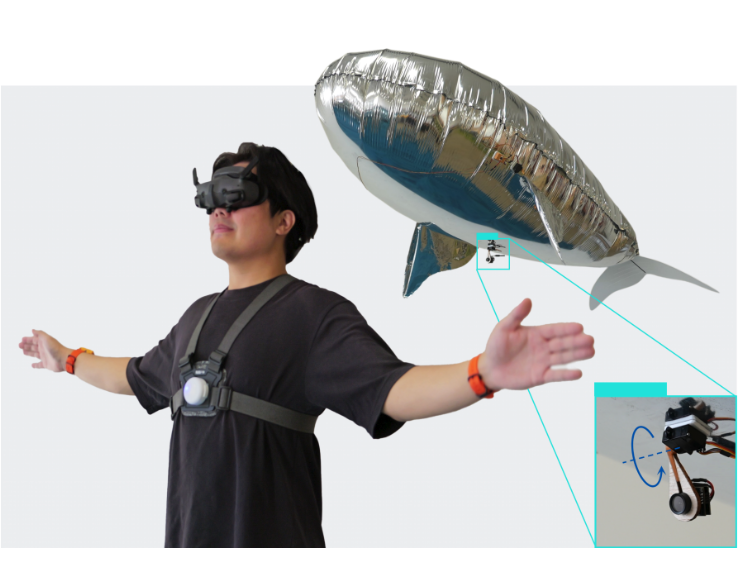
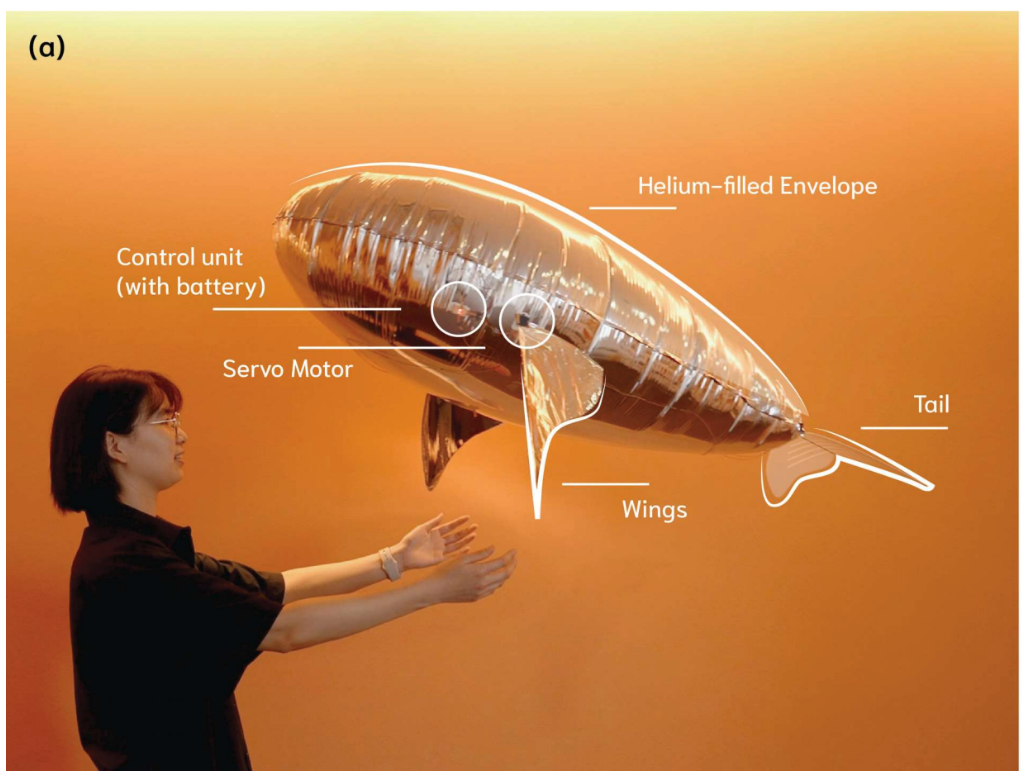
Spread Your Wings: Demonstrating a Soft Floating Robotic Avatar with Flapping Wings for Novel Physical Interactions
Mingyang Xu, Yulan Ju, Qing Zhang, and 7 more authors
@incollection{xu2025spread,title={Spread Your Wings: Demonstrating a Soft Floating Robotic Avatar with Flapping Wings for Novel Physical Interactions},author={Xu, Mingyang and Ju, Yulan and Zhang, Qing and Kim, Christopher Changmok and Gao, Qingyuan and Pai, Yun Suen and Barbareschi, Giulia and Hoppe, Matthias and Kunze, Kai and Minamizawa, Kouta},booktitle={ACM SIGGRAPH 2025 Emerging Technologies},pages={1--2},year={2025},doi={https://doi.org/10.1145/3721257.3734034},}
Arxiv
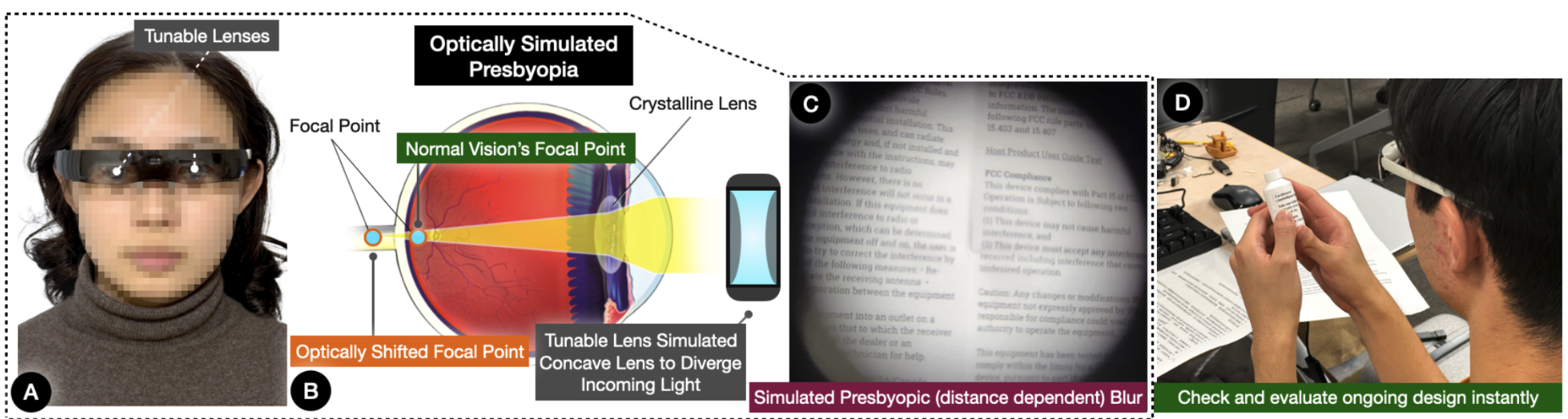
OpticalAging: Real-time Presbyopia Simulation for Inclusive Design via Tunable Lenses
Qing Zhang, Zixiong Su, Yoshihito Kondoh, and 5 more authors
Presbyopia, a common age-related vision condition affecting most people as they age, often remains inadequately understood by those unaffected. To help bridge the gap between abstract accessibility knowledge and a more grounded appreciation of perceptual challenges, this study presents OpticalAging, an optical see-through simulation approach. Unlike VR-based methods, OpticalAging uses dynamically controlled tunable lenses to simulate the first-person visual perspective of presbyopia’s distance-dependent blur during real-world interaction, aiming to enhance awareness. While acknowledging critiques regarding simulation’s limitations in fully capturing lived experience, we position this tool as a complement to user-centered methods. Our user study (N = 19, 18-35 years old) provides validation: quantitative measurements show statistically significant changes in near points across three age modes (40s, 50s, 60s), while qualitative results suggest increases in reported understanding and empathy among participants. The integration of our tool into a design task showcases its potential applicability within age-inclusive design workflows when used critically alongside direct user engagement.
@article{zhang2025opticalaging,title={OpticalAging: Real-time Presbyopia Simulation for Inclusive Design via Tunable Lenses},author={Zhang, Qing and Su, Zixiong and Kondoh, Yoshihito and Asada, Kazunori and Starner, Thad and Kunze, Kai and Itoh, Yuta and Rekimoto, Jun},journal={arXiv preprint arXiv:2506.19307},year={2025},}
AHs Poster
Look and Talk: Seamless AI Assistant Interaction with Gaze-Triggered Activation
Engaging with AI assistants to gather essential information in a timely manner is becoming increasingly common. Traditional activation methods, like wake words such as Hey Siri, Ok Google, and Hey Alexa, are constrained by technical challenges such as false activations, recognition errors, and discomfort in public settings. Similarly, activating AI systems via physical buttons imposes strict interactive limitations as it demands particular physical actions, which hinders fluid and spontaneous communication with AI. Our approach employs eye-tracking technology within AR glasses to discern a user’s intention to engage with the AI assistant. By sustaining eye contact on a virtual AI avatar for a specific time, users can initiate an interaction silently and without using their hands. Preliminary user feedback suggests that this technique is relatively intuitive, natural, and less obtrusive, highlighting its potential for integrating AI assistants fluidly into everyday interactions.
@article{qing2025look,title={Look and Talk: Seamless AI Assistant Interaction with Gaze-Triggered Activation},author={Zhang, Qing and Rekimoto, Jun},doi={https://dl.acm.org/doi/10.1145/3745900.3746107},year={2025},}
AHs Paper
Cuddle-Fish: Exploring a Soft Floating Robot with Flapping Wings for Physical Interactions
Mingyang Xu, Jiayi Shao, Yulan Ju, and 8 more authors
In Proceedings of the Augmented Humans International Conference 2025, 2025
We present Cuddle-Fish, a soft flapping-wing floating robot designed for close-proximity interactions in indoor spaces. Through a user study with 24 participants, we explored their perceptions of the robot and experiences during a series of co-located demonstrations in which the robot moved near them. Results showed that participants felt safe, willingly engaged in touch-based interactions with the robot, and exhibited spontaneous affective behaviours, such as patting, stroking, hugging, and cheek-touching, without external prompting. They also reported positive emotional responses towards the robot. These findings suggest that the soft floating robot with flapping wings can serve as a novel and socially acceptable alternative to traditional rigid flying robots, opening new potential for applications in companionship, affective interaction, and play in everyday indoor environments.
@inproceedings{xu2025cuddle,title={Cuddle-Fish: Exploring a Soft Floating Robot with Flapping Wings for Physical Interactions},author={Xu, Mingyang and Shao, Jiayi and Ju, Yulan and Shen, Ximing and Gao, Qingyuan and Chen, Weijen and Zhang, Qing and Pai, Yun Suen and Barbareschi, Giulia and Hoppe, Matthias and others},booktitle={Proceedings of the Augmented Humans International Conference 2025},pages={160--173},year={2025},doi={https://dl.acm.org/doi/full/10.1145/3745900.3746080},}
VR Workshop
AutoGaze: A Very Initial Exploration in A SAM2-based Pipeline for Automated Eye-Object Interaction Analysis in First-Person Videos
Qing Zhang, Yifei Huang, and Jun Rekimoto
In 2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), 2025
This paper presents a novel automated workflow for analyzing eye-tracking data in first-person videos. Our system uses the Segment Anything Model 2 (SAM2) to segment and track objects, correlating them with gaze information to provide a detailed understanding of visual attention and hand-object interactions. The pipeline outputs a structured JSON file containing rich information about gaze behavior, object interactions, and their temporal relationships. We demonstrate the system’s effectiveness in a life science operational context and compare its performance with a multimodal Large Language Model (LLM) for automated annotation. Our findings highlight the potential of combining advanced computer vision techniques with LLMs for comprehensive and scalable analysis of gaze behavior in real-world scenarios.
@inproceedings{zhang2025autogaze,title={AutoGaze: A Very Initial Exploration in A SAM2-based Pipeline for Automated Eye-Object Interaction Analysis in First-Person Videos},author={Zhang, Qing and Huang, Yifei and Rekimoto, Jun},booktitle={2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW)},pages={897--900},year={2025},organization={IEEE},doi={10.1109/VRW66409.2025.00183},}
2024
SIGGRAPH Asia Poster
Affective Wings: Exploring Affectionate Behaviors in Close-Proximity Interactions with Soft Floating Robots
Mingyang Xu, Yulan Ju, Yunkai Qi, and 6 more authors
@incollection{xu2024affective,title={Affective Wings: Exploring Affectionate Behaviors in Close-Proximity Interactions with Soft Floating Robots},author={Xu, Mingyang and Ju, Yulan and Qi, Yunkai and Meng, Xiaru and Zhang, Qing and Hoppe, Matthias and Minamizawa, Kouta and Barbareschi, Giulia and Kunze, Kai},booktitle={SIGGRAPH Asia 2024 Posters},pages={1--3},year={2024},}
UIST Poster
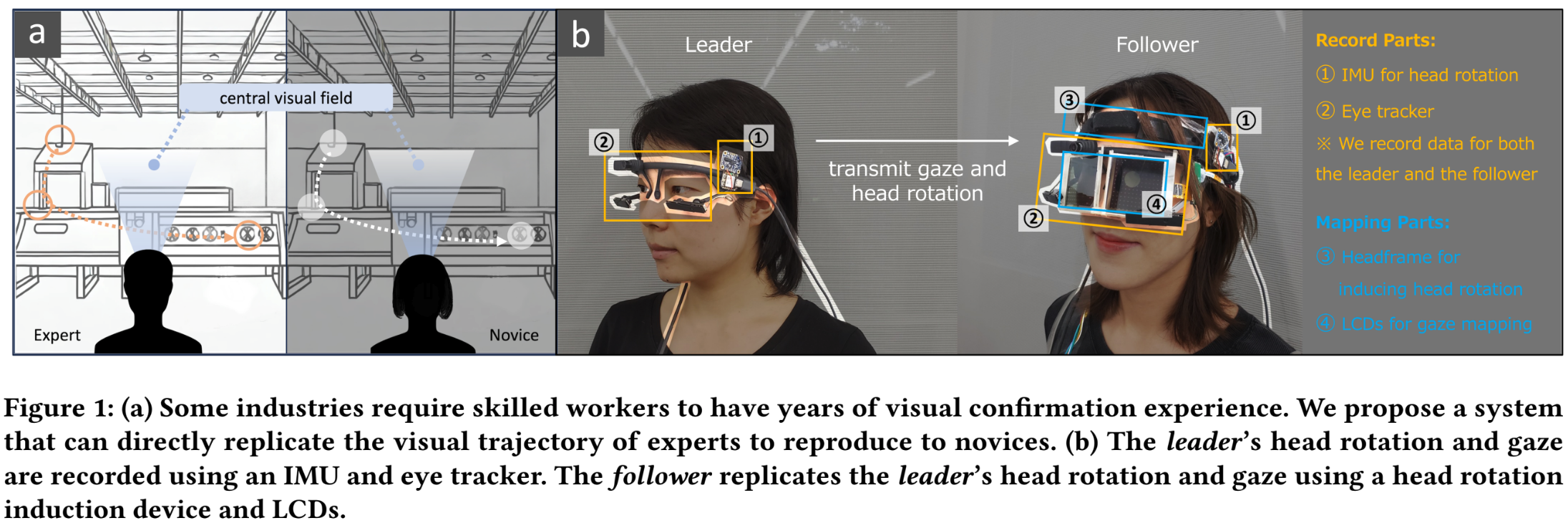
Mapping Gaze and Head Movement via Salience Modulation and Hanger Reflex
Wanhui Li, Qing Zhang, Takuto Nakamura, and 2 more authors
In Adjunct Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, 2024
Vision is crucial for daily input and plays a significant role in remote collaboration. Sharing gaze has been explored to enhance communication, but sharing gaze alone is not natural due to limited central vision (30 degrees). We propose a novel approach to map gaze and head movements simultaneously, enabling replicating natural observation across individuals. In this paper, we evaluate the effectiveness of replication head movements and gaze on another person by a pilot study. In the future, we will also explore the possibility of improving novices’ efficiency in imitating experts by replicating the gaze trajectories of experts.
@inproceedings{li2024mapping,title={Mapping Gaze and Head Movement via Salience Modulation and Hanger Reflex},author={Li, Wanhui and Zhang, Qing and Nakamura, Takuto and Lai, Sinyu and Rekimoto, Jun},booktitle={Adjunct Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology},pages={1--3},year={2024},doi={https://doi.org/10.1145/3672539.3686349}}
SUI Demo
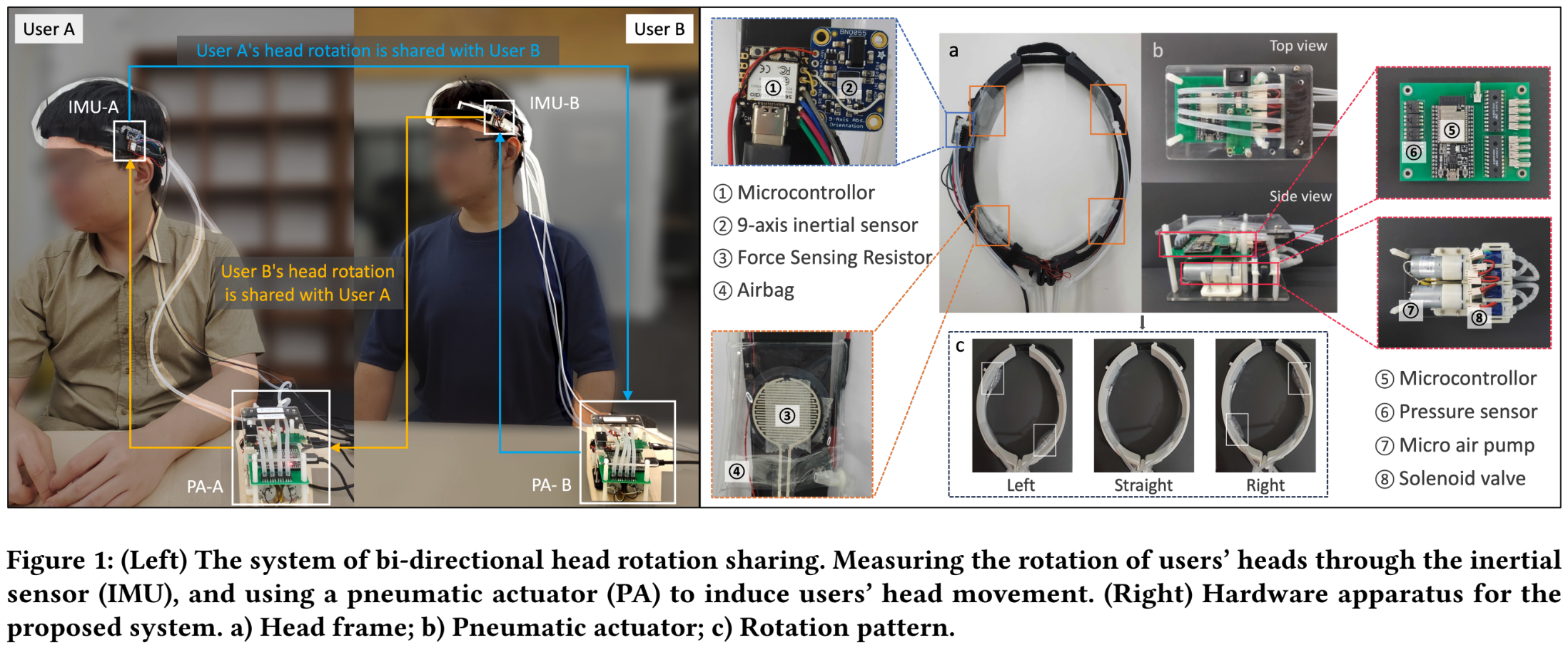
Real-Time Bidirectional Head Rotation Sharing for Collaborative Interaction Enhancement
Wanhui Li, Takuto Nakamura, Qing Zhang, and 1 more author
In Proceedings of the 2024 ACM Symposium on Spatial User Interaction, 2024
Remote collaboration is becoming more prevalent, yet it often struggles with effectively conveying the spatial orientation of a remote participant. We introduce an innovative communication method that enables users to share their head direction. While traditional methods like written text and spoken language suit most situations, new approaches are necessary for scenarios lacking sufficient visual or auditory cues. For instance, how can hearing-impaired individuals share directional information during a remote collaborative game? This research presents an interactive system that induces head rotation based on the other user’s head direction, allowing users to grasp each other’s intended direction intuitively. This system improves communication by offering an additional means to share directional cues, especially in settings where visual and auditory cues are inadequate.
@inproceedings{li2024real,title={Real-Time Bidirectional Head Rotation Sharing for Collaborative Interaction Enhancement},author={Li, Wanhui and Nakamura, Takuto and Zhang, Qing and Rekimoto, Jun},booktitle={Proceedings of the 2024 ACM Symposium on Spatial User Interaction},pages={1--3},year={2024},}
AHs Poster
Aged Eyes: Optically Simulating Presbyopia Using Tunable Lenses
Qing Zhang, Yoshihito Kondoh, Yuta Itoh, and 1 more author
In Proceedings of the Augmented Humans International Conference 2024, 2024
@inproceedings{zhang2024aged,title={Aged Eyes: Optically Simulating Presbyopia Using Tunable Lenses},author={Zhang, Qing and Kondoh, Yoshihito and Itoh, Yuta and Rekimoto, Jun},booktitle={Proceedings of the Augmented Humans International Conference 2024},pages={294--297},year={2024},}
2023
CHI LBW
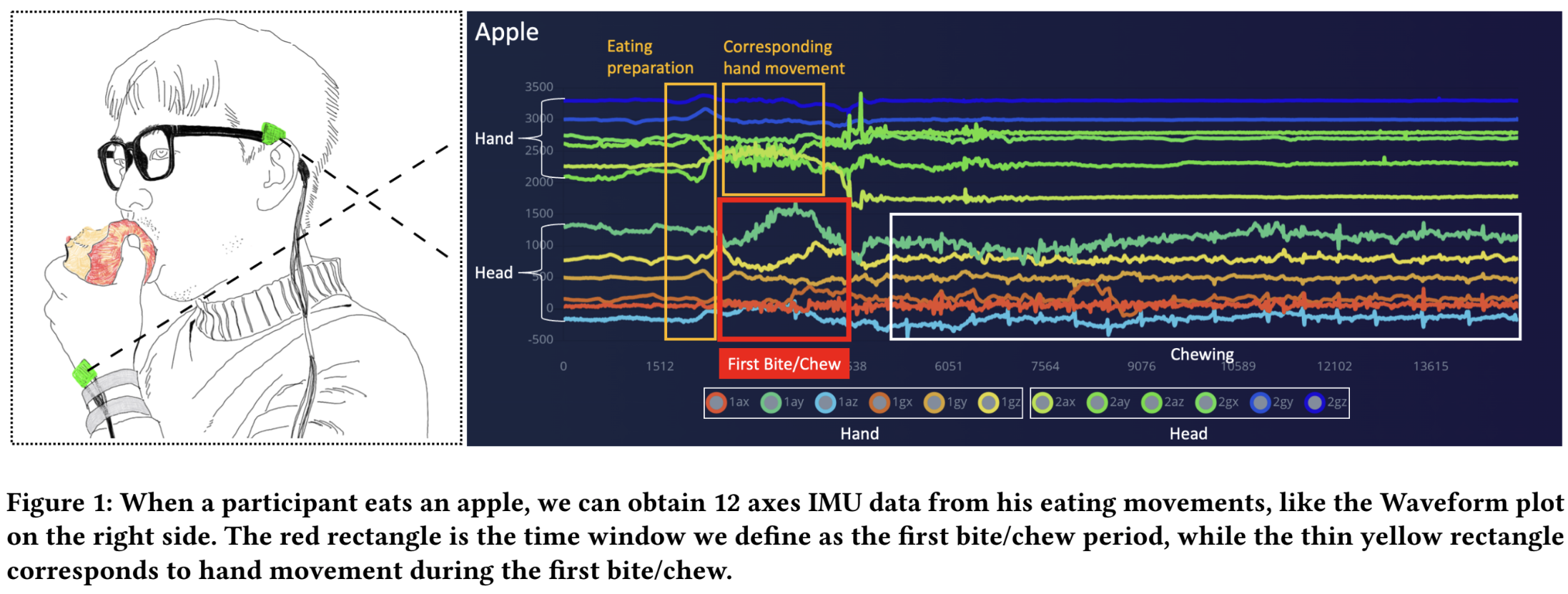
First Bite/Chew: distinguish different types of food by first biting/chewing and the corresponding hand movement
Junyu Chen, Xiongqi Wang, Juling Li, and 6 more authors
In Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, 2023
@inproceedings{chen2023first,title={First Bite/Chew: distinguish different types of food by first biting/chewing and the corresponding hand movement},author={Chen, Junyu and Wang, Xiongqi and Li, Juling and Chernyshov, George and Huang, Yifei and Kunze, Kai and Huang, Jing and Starner, Thad and Zhang, Qing},booktitle={Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems},pages={1--7},year={2023},doi={https://doi.org/10.1145/3544549.3585845}}
AHs Poster
First Bite/Chew: distinguish typical allergic food by two IMUs
Juling Li, Xiongqi Wang, Junyu Chen, and 6 more authors
In Proceedings of the Augmented Humans International Conference 2023, 2023
@inproceedings{li2023first,title={First Bite/Chew: distinguish typical allergic food by two IMUs},author={Li, Juling and Wang, Xiongqi and Chen, Junyu and Starner, Thad and Chernyshov, George and Huang, Jing and Huang, Yifei and Kunze, Kai and Zhang, Qing},booktitle={Proceedings of the Augmented Humans International Conference 2023},pages={326--329},year={2023},}
2022
UIST Paper
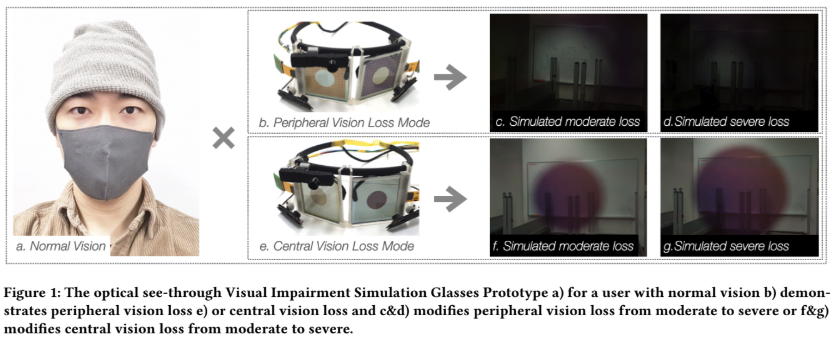
Seeing our blind spots: smart glasses-based simulation to increase design students’ awareness of visual impairment
Qing Zhang, Giulia Barbareschi, Yifei Huang, and 4 more authors
In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology, 2022
As the population ages, many will acquire visual impairments. To improve design for these users, it is essential to build awareness of their perspective during everyday routines, especially for design students. Although several visual impairment simulation toolkits exist in both academia and as commercial products, analog, and static visual impairment simulation tools do not simulate effects concerning the user’s eye movements. Meanwhile, VR and video see-through-based AR simulation methods are constrained by smaller fields of view when compared with the natural human visual field and also suffer from vergence-accommodation conflict (VAC) which correlates with visual fatigue, headache, and dizziness. In this paper, we enable an on-the-go, VAC-free, visually impaired experience by leveraging our optical see-through glasses. The FOV of our glasses is approximately 160 degrees for horizontal and 140 degrees for vertical, and participants can experience both losses of central vision and loss of peripheral vision at different severities. Our evaluation (n =14) indicates that the glasses can significantly and effectively reduce visual acuity and visual field without causing typical motion sickness symptoms such as headaches and or visual fatigue. Questionnaires and qualitative feedback also showed how the glasses helped to increase participants’ awareness of visual impairment.
@inproceedings{zhang2022seeing,title={Seeing our blind spots: smart glasses-based simulation to increase design students’ awareness of visual impairment},author={Zhang, Qing and Barbareschi, Giulia and Huang, Yifei and Li, Juling and Pai, Yun Suen and Ward, Jamie and Kunze, Kai},booktitle={Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology},pages={1--14},year={2022},doi={https://doi.org/10.1145/3526113.3545687}}
UIST Demo
Experience Visual Impairment via Optical See-through Smart Glasses
Qing Zhang, Xiongqi Wang, Thad Starner, and 8 more authors
In Adjunct Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology, 2022
@inproceedings{zhang2022experience,title={Experience Visual Impairment via Optical See-through Smart Glasses},author={Zhang, Qing and Wang, Xiongqi and Starner, Thad and Huang, Yifei and Chernyshov, George and Barbareschi, Giulia and Pai, Yun Suen and Huang, Jing and Yamaoka, Junichi and Ward, Jamie and others},booktitle={Adjunct Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology},pages={1--2},year={2022},doi={https://doi.org/10.1145/3526114.3558617}}
SA’ Art Gallery
Inner self drawing machine
Qing Zhang, Fan Xie, Yifei Huang, and 6 more authors
In The ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia, Art Gallery, 2022
Besides men and women, people can be neither man nor woman, fluid identity, transgender, and agender. Not only that, in terms of sexual orientation, besides heterosexuals, there are homosexuals, bisexuals, pansexuals, and asexuals as well. However, ignorance and lacking empathetic understanding of those sexual minorities make their lives harsh and suffering. For instance, in the case of transgender people, 28% of them postponed their health care due to discrimination, 19% of them refused medical care altogether, and 28% of them experienced verbal harassment by medical professionals, according to a 2011 national transgender discrimination survey (USA). Unluckily, we are apt to generate a basic understanding of others based on their gender expressions and use such irresponsible and heuristic findings to deal with others. Thus, we decided to create an installation to at least minimize the gap for a moment when the audience can enjoy themselves by watching the drawing performance of their idea portrait (inner-self). Regarding the AI portrait painter, we leverage StyleGAN to generate the continuous gender spectrum of each participant based on their facial features, in which they can choose their ideal gender representation that reflects their inner self the most. Then our AI portrait painter "draws" the selected "self" on the canvas. In general professional painters can detect and draw the most confident and beautiful us, on the other hand, we tend to exaggerate our flaws and ignore our attractive parts. When the drawing performance finishes, the audience can receive the drawing result as a well-printed portrait simultaneously. The printed portrait also works as a souvenir of participating in our exhibition. Our work aims to raise an empathic understanding of the various sexual minorities for a more inclusive, preferable, and sustainable world.
@inproceedings{zhang2022inner,title={Inner self drawing machine},author={Zhang, Qing and Xie, Fan and Huang, Yifei and Yun, Suen Pai and George, Chernyshov and Huang, Jing and Wang, Xiongqi and Jamie A., Ward and Kai, Kunze},booktitle={The ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia, Art Gallery},year={2022},doi={https://doi.org/10.1145/3550470.3558429}}
IUI Poster
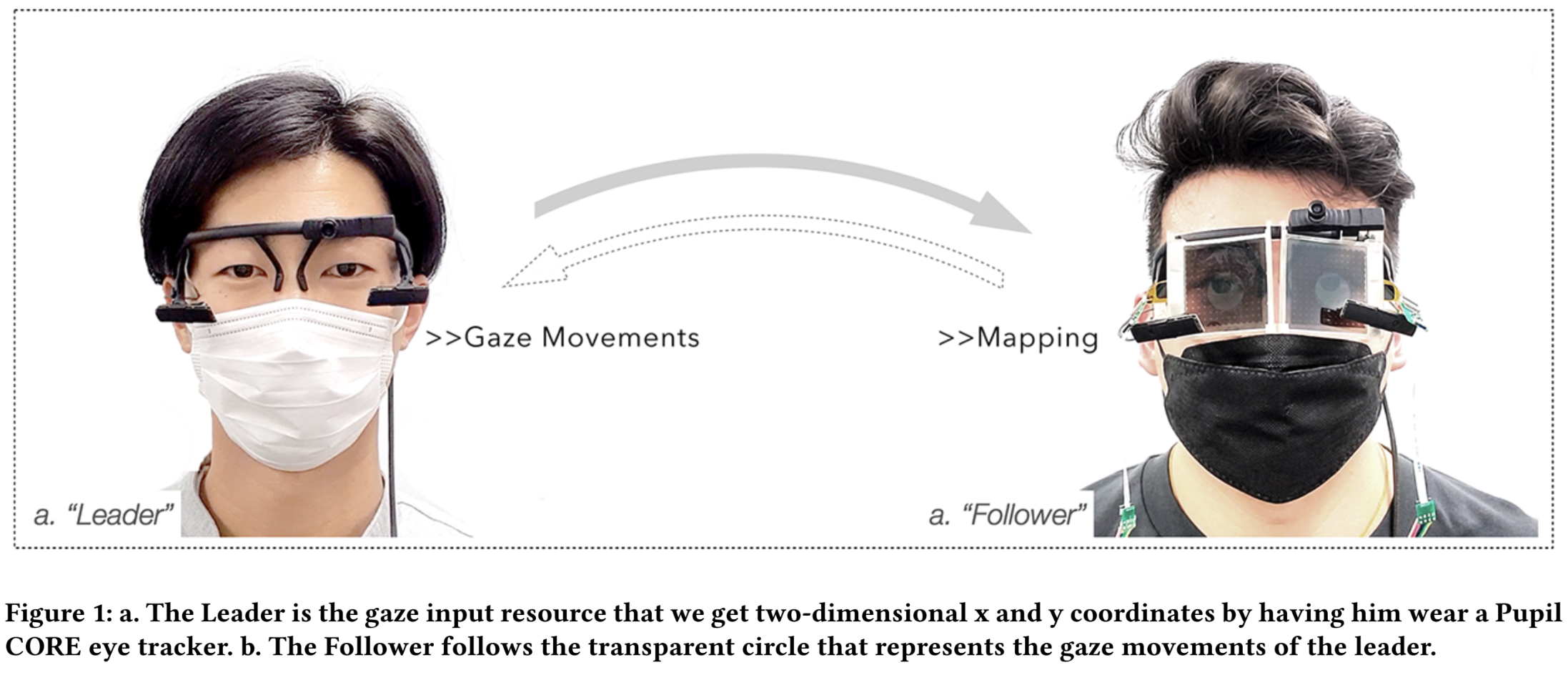
GazeSync: Eye movement transfer using an optical eye tracker and monochrome liquid crystal displays
Qing Zhang, Yifei Huang, George Chernyshov, and 3 more authors
In Companion Proceedings of the 27th International Conference on Intelligent User Interfaces, 2022
Can we see the world through the eyes of somebody else? We present an early work to transfer eye gaze from one person to another. Imagine you can follow the eye gaze of an instructor while explaining a complex work step, or you can experience a painting like an expert would: Your gaze is directed to the important parts and follows the appropriate steps. In this work, we explore the possibility to transmit eye-gaze information in a subtle, unobtrusive fashion between two individuals. We present an early prototype consisting of an optical eye-tracker for the leader (person who shares the eye gaze) and two monochrome see-through displays for the follower (person who follows the eye gaze of the leader). We report the results of an initial user test and discuss future works.
@inproceedings{zhang2022gazesync,title={GazeSync: Eye movement transfer using an optical eye tracker and monochrome liquid crystal displays},author={Zhang, Qing and Huang, Yifei and Chernyshov, George and Li, Juling and Pai, Yun Suen and Kunze, Kai},booktitle={Companion Proceedings of the 27th International Conference on Intelligent User Interfaces},pages={54--57},year={2022},doi={https://doi.org/10.1145/3490100.3516469},}
CHI’ DC
Programmable Peripheral Vision: augment/reshape human visual perception
Qing Zhang
In CHI Conference on Human Factors in Computing Systems Extended Abstracts, 2022
Over time our daily visual tasks become more complex continuously, however, the natural adaptation of our visual system does not adapt as fast as the living environment changes. As the representations of this unbalanced trend, concentration difficulty and visual overload are experienced and studied intensively. As well as universal motion sickness occurs in both real-life and virtual environments. Besides, online learning and co-working experience are far from satisfactory, which is partly due to lacking engagement and instantaneous visual interaction that we used to have when conducting those activities offline. Thus, my goal is to propose methods helping us better adapt to rapidly changing visual contexts. In the formative research, I created dynamic peripheral vision blocking glasses, and its experimental result indicates that wearing such glasses helped its users suffer fewer motion sickness symptoms while accessing fast-moving surrounding scenery in a VR environment. For the following studies, I am creating dynamic saliency adjusting glasses and gaze guiding glasses to augment and reshape daily-life visual perception.
@inproceedings{zhang2022programmable,title={Programmable Peripheral Vision: augment/reshape human visual perception},author={Zhang, Qing},booktitle={CHI Conference on Human Factors in Computing Systems Extended Abstracts},pages={1--5},year={2022},doi={https://doi.org/10.1145/3491101.3503821}}
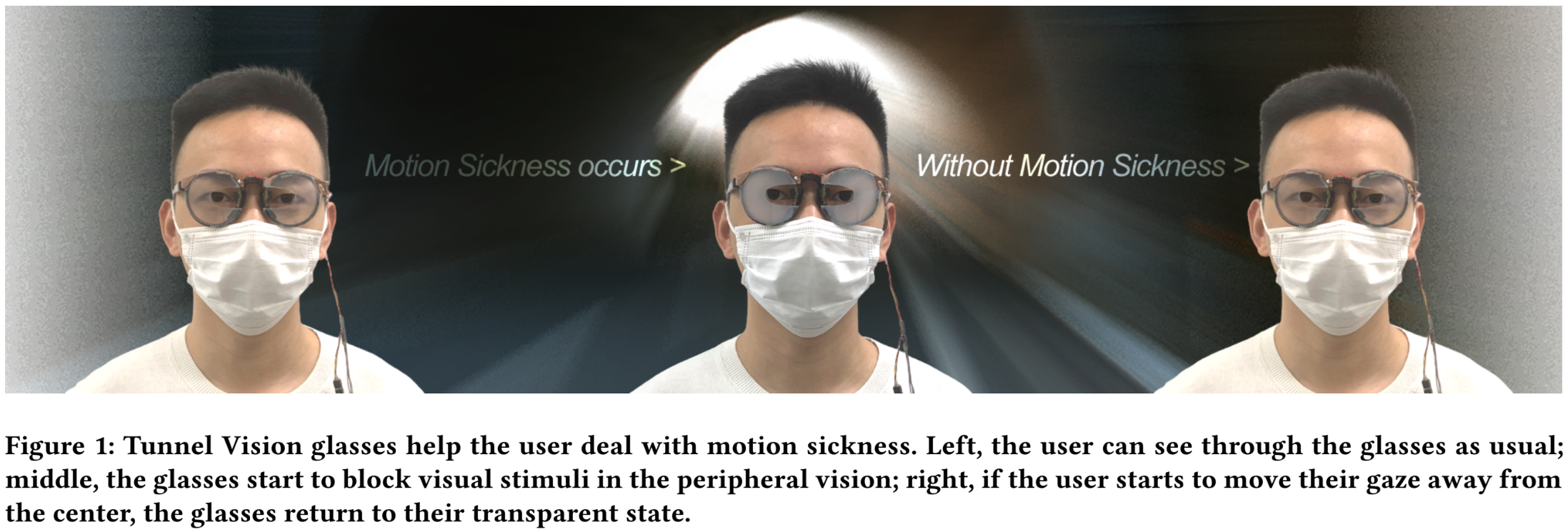
Motion sickness affects roughly a third of all people. Narrowing the field of view (FOV) can help to reduce motion sickness symptoms. In this paper, we present Tunnel Vision, a type of smart glasses that can dynamically block a wearer’s peripheral vision area using switchable polymer dispersed liquid crystal (PDLC) film. We evaluate the prototype in a virtual reality environment. Our experiments (n=19) suggest that Tunnel Vision statistically significantly reduces the following Simulator Sickness Questionnaire (SSQ) related motion sickness symptoms without impacting immersion: ”difficulty concentrating” (F(2,35) = 4.121, p = 0.025), ”head feeling heavy” (F(2,35) = 3.231, p = 0.051) and ”nausea” (F(2,35) = 3.145, p = 0.055).
@inproceedings{zhang2021tunnel,title={Tunnel vision--dynamic peripheral vision blocking glasses for reducing motion sickness symptoms},author={Zhang, Qing and Yamamura, Hiroo and Baldauf, Holger and Zheng, Dingding and Chen, Kanyu and Yamaoka, Junichi and Kunze, Kai},booktitle={Proceedings of the 2021 ACM International Symposium on Wearable Computers},pages={48--52},year={2021},doi={https://doi.org/10.1145/3460421.3478824},}



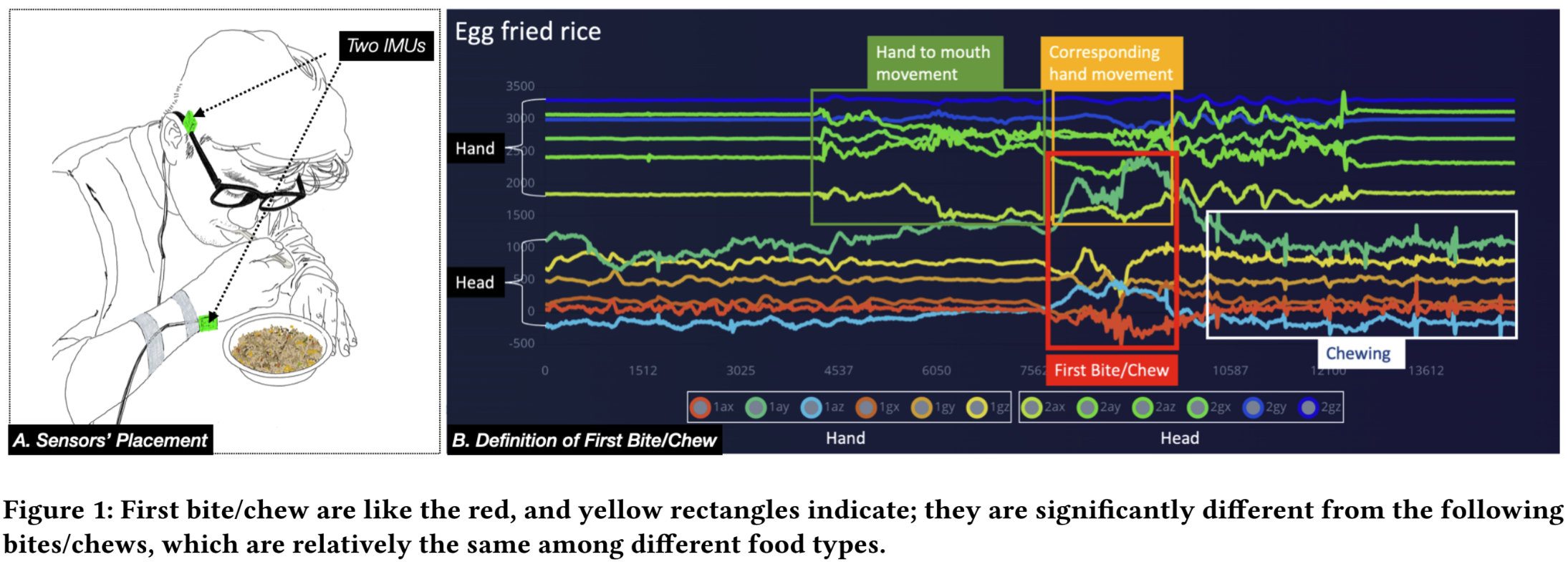 First Bite/Chew: distinguish typical allergic food by two IMUsIn Proceedings of the Augmented Humans International Conference 2023, 2023
First Bite/Chew: distinguish typical allergic food by two IMUsIn Proceedings of the Augmented Humans International Conference 2023, 2023